Recently, someone asked me about the social assessment proposed by the Orienting project [1], specifically about the social databases compared there. I admit I was not aware, so I checked. Lead authors of the report and deliverable are Rosan Harmens and Mark Goedkoop from PRé, Mark being the long-time CEO and founder [2]. There are two databases compared, SHDB and PSILCA.
The comparison of the two databases is summarized in table 12, pasted below. As you see, both databases are assessed to be quite similar, also regarding transparency.
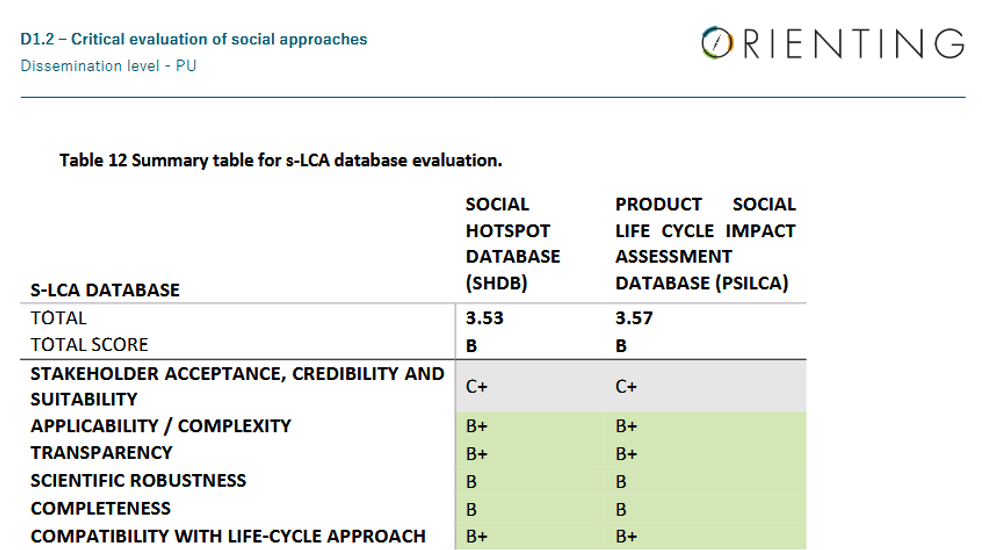
the SLCA database comparison table from the Orienting project [2]
While overall the evaluation is really positive, I was quite surprised. Some history, we had initially prepared, more than ten years ago and in collaboration with Greg Norris, the SHDB for LCA tools (for openLCA and also for SimaPro), and then decided to make our own database, PSILCA, because we found the SHDB not being sufficiently transparent, as it contains only risk-assessed worker hour flows. Users cannot change the risk levels of indicators.
Thus we created “the other” database, PSILCA, and in this database
- Show risk-assessed worker hours
- Show also the raw indicator values
- Users can change the risk assessment of the social indicators
- For all indicators, there are sources provide
- The data quality of all flows is assessed, the assessment is shown and can be considered in an LCA calculation.
Points 2 to 5 are not shown and not provided in the SHDB. In addition, we have written a comprehensive, 130 pages handbook for the database which is publicly available, while the SHDB comes with a 30 page documentation. You can calculate the PSILCA database with worker hours or also directly over the indicators, in openLCA.
Let’s look at one example, a process dataset for milk in Brazil, in both databases. The specific amounts are not so important but the structure. We need to differentiate by database (SHDB and PSILCA) and by tool (openLCA and SimaPro).
So, in PSILCA and openLCA (milk from cows and other animals)
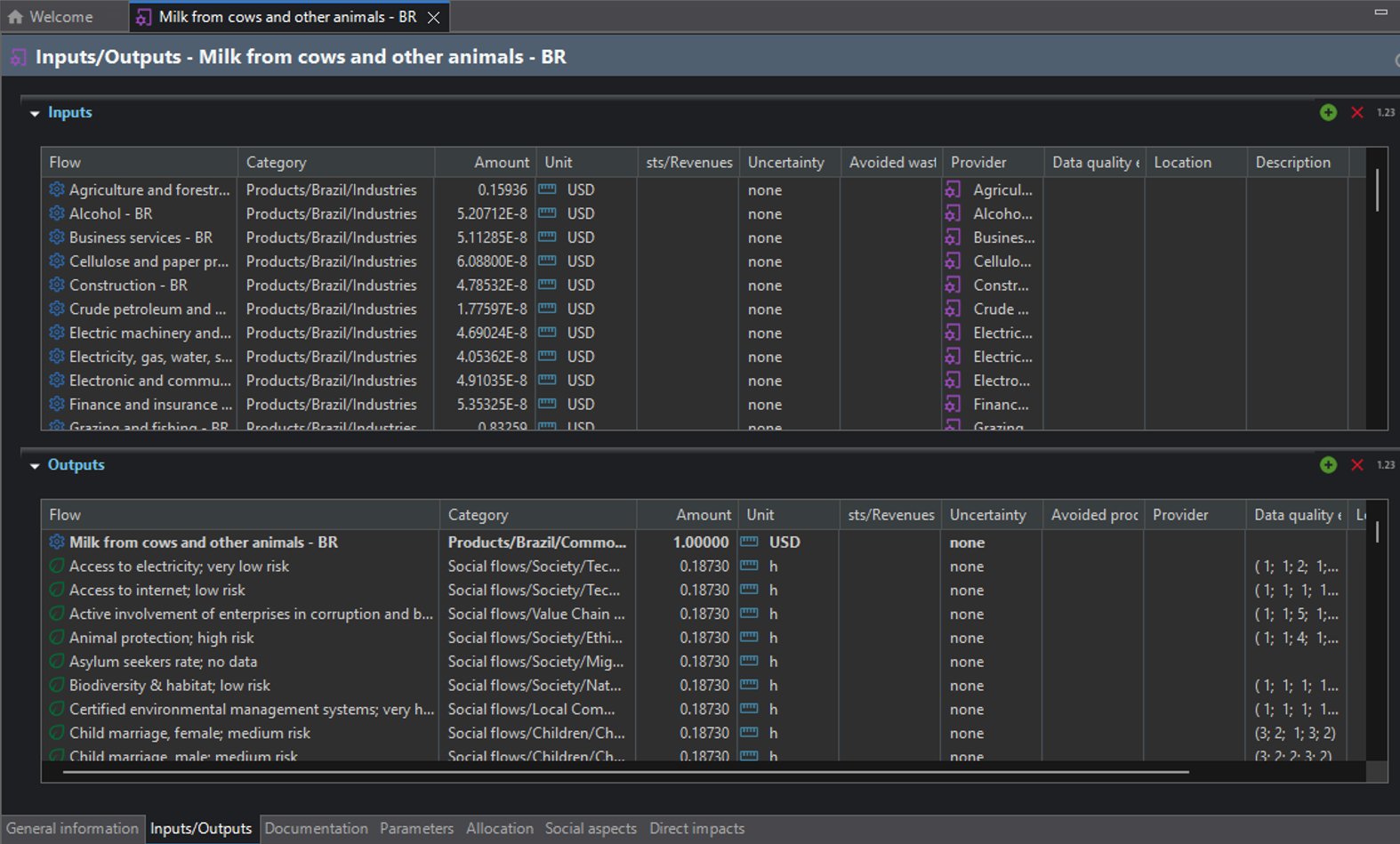
process excerpt ‘milk from cows and other animals’, PSILCA, openLCA, IO sheet
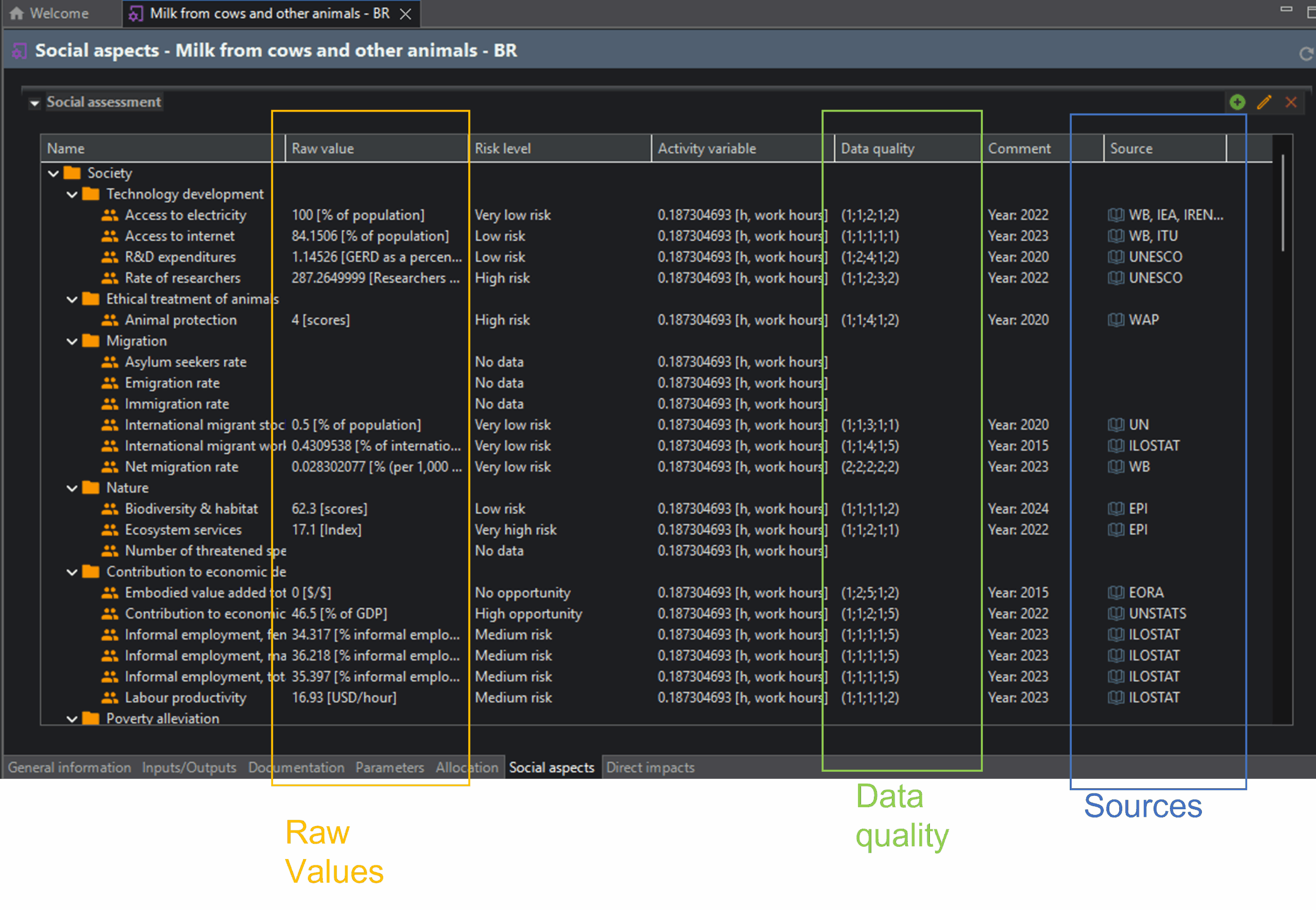
process excerpt ‘milk from cows and other animals’, PSILCA, openLCA, social aspects sheet
I highlighted the raw values (non-risk assessed indicator values), data quality, and sources.
And for the SHDB, a similar process raw milk in Brazil looks as follows
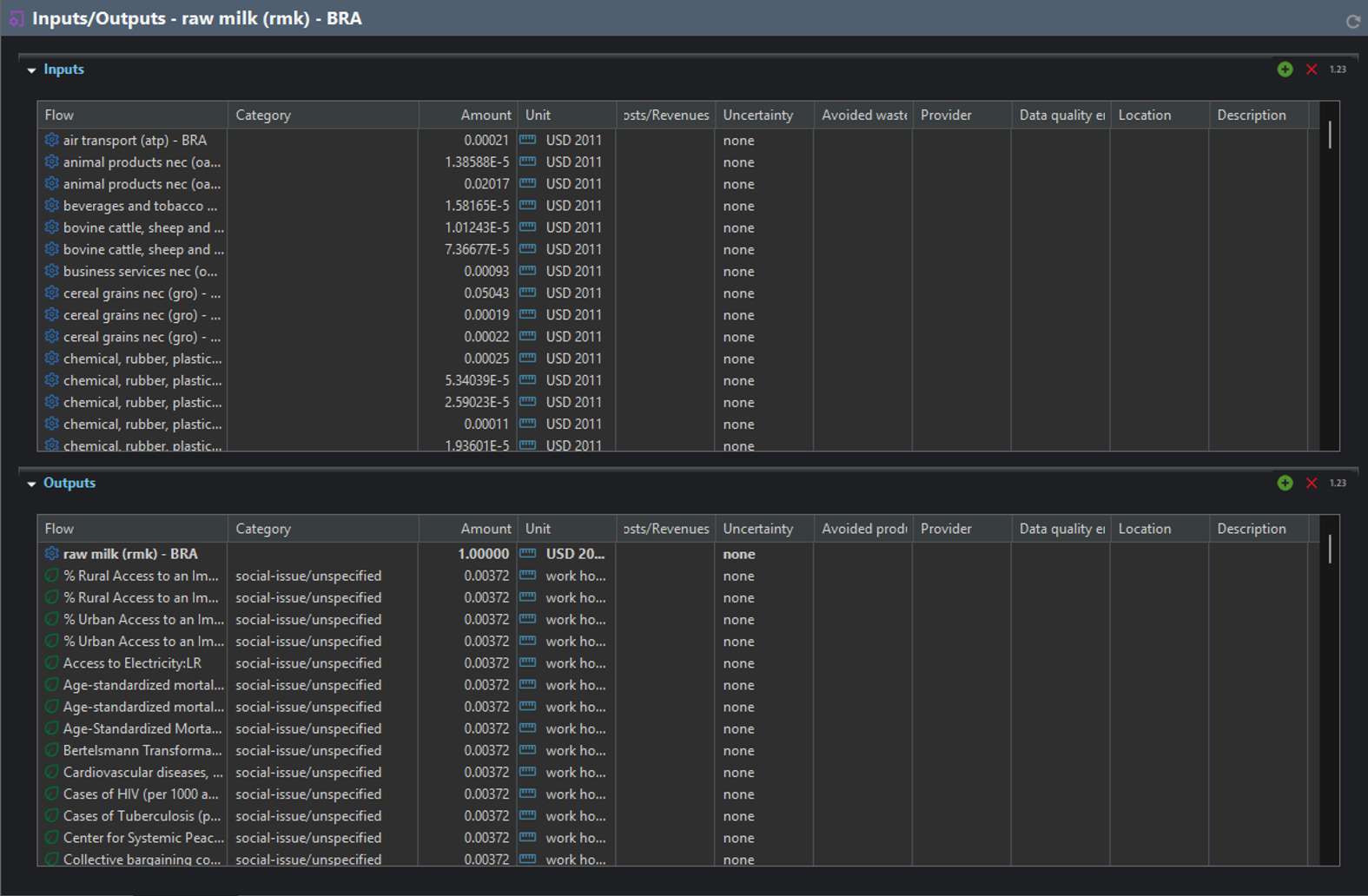
process excerpt ‘raw milk in Brazil’, SHDB, openLCA, IO sheet
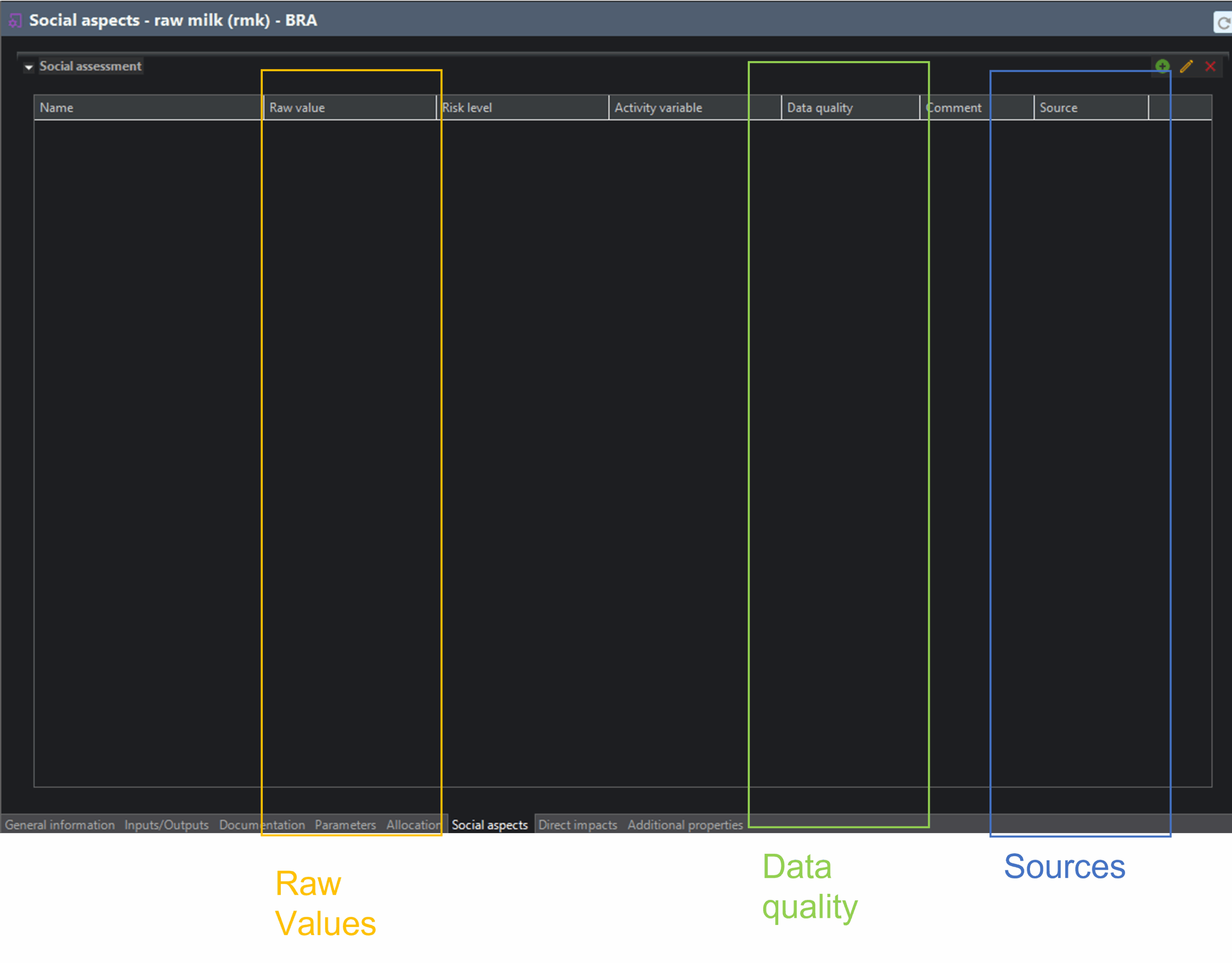
process excerpt ‘raw milk in Brazil’, SHDB, openLCA, social aspects sheet
So why are these databases assessed to be equally transparent, in the orienting deliverable? Of course I do not exactly know and this is somewhat speculative, but I see several possibilities:
1, direct commercial interest. PRé is reseller of the SHDB database, and a reseller typically gets a commission for a sale. SHDB is available on the SimaPro website for purchase [3]. For PSILCA, PRé does not get a commission. We declined to have our database on the PRé site exactly because PRé back then required a steep commission. I am not aware of the details here but it could be around 30% of the sales price.
2, indirect commercial interest. PRé is developer of the SimaPro LCA tool. This tool is on the market since about 30 years and has seen rather minor changes in the last 15 years I am aware of. In SimaPro, the novel features we have implemented in PSILCA (raw values, data quality calculation, change of the risk assessment via script) are not available. In SimaPro, both databases look quite similar, see the screenshots below.
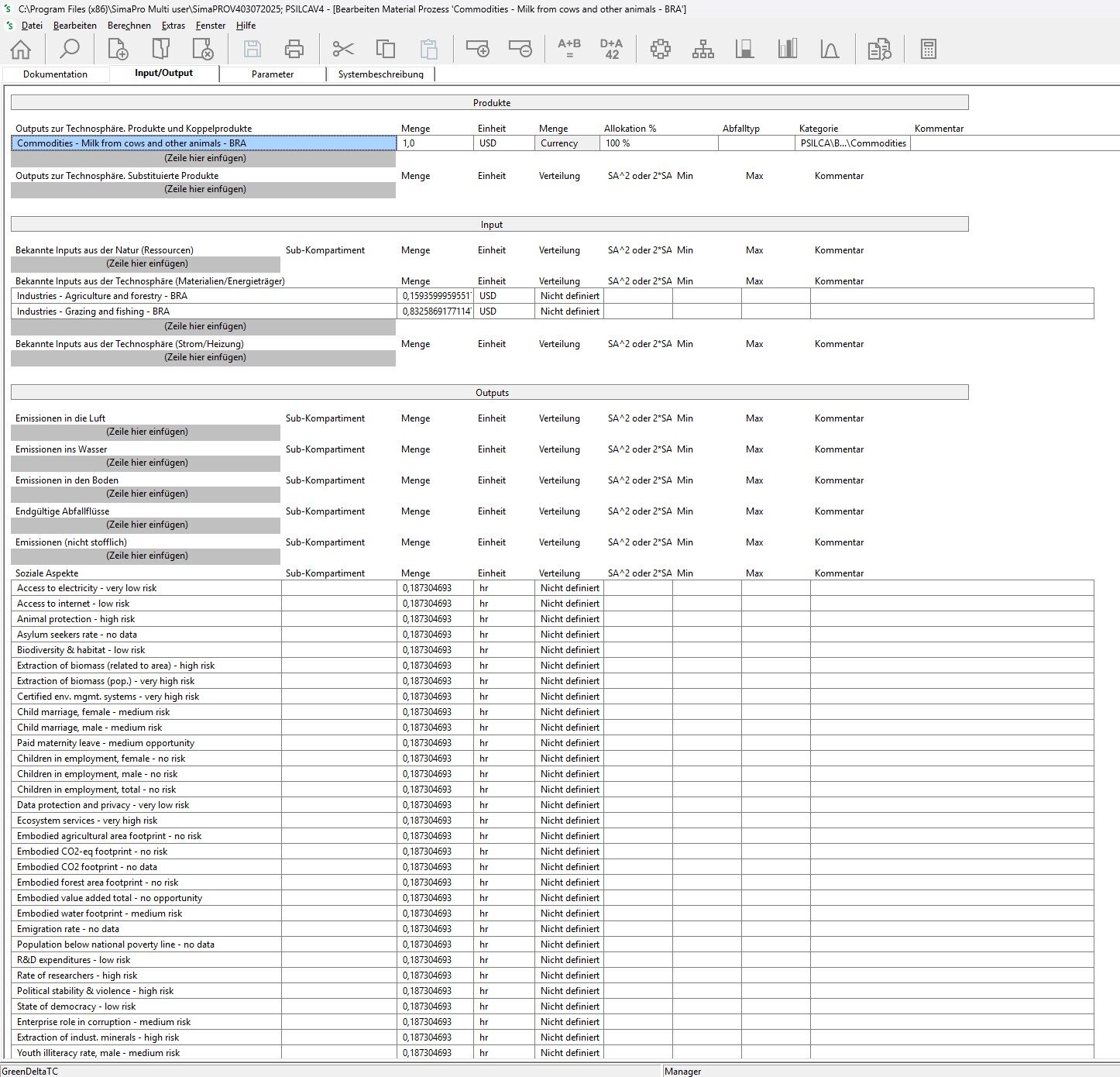
process excerpt ‘milk from cows and other animals’, PSILCA, SimaPro
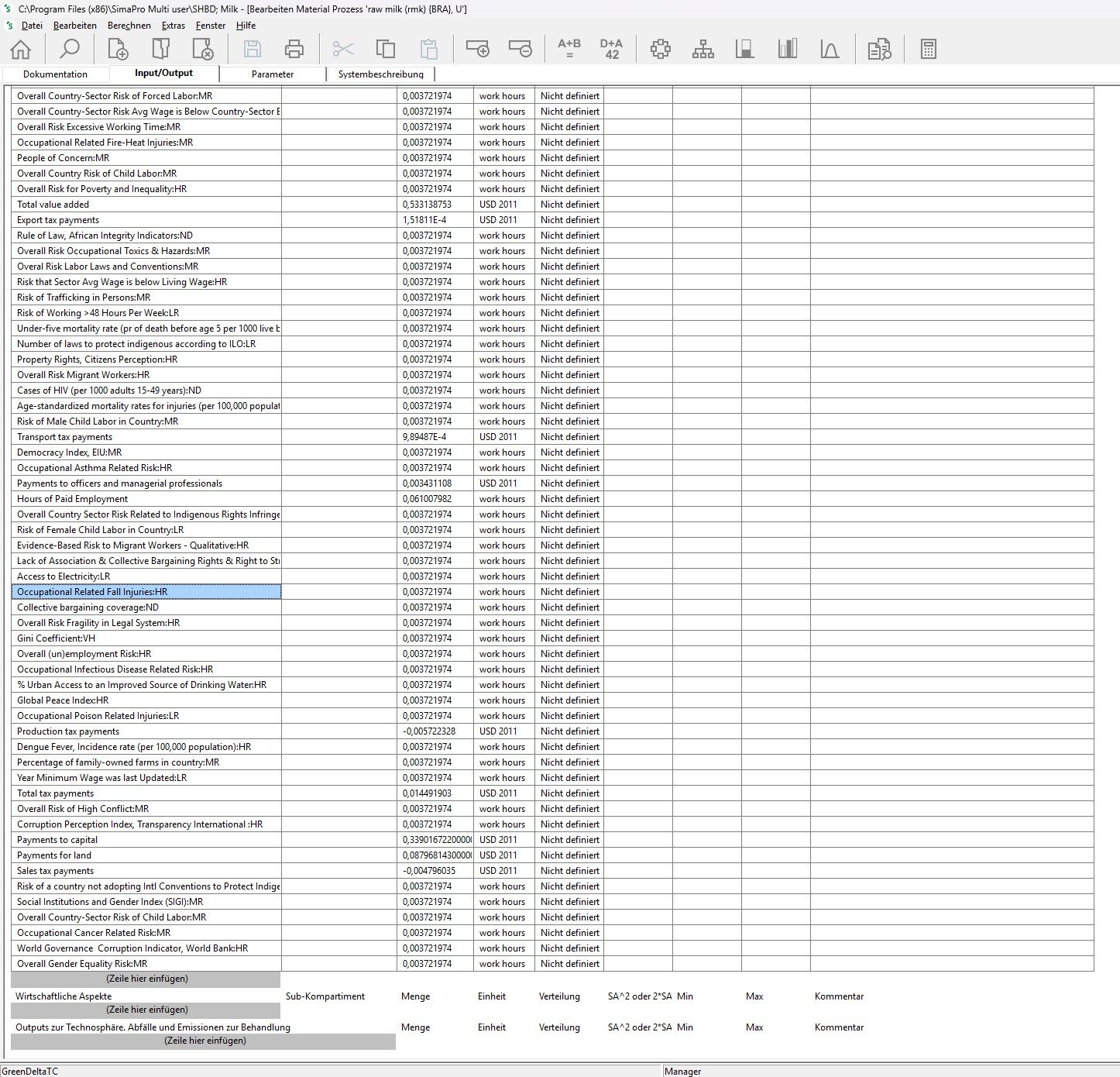
process excerpt ‘raw milk in Brazil’, SHDB, SimaPro
Admitting that a database is better in a tool that is not the own tool could be negative for the own tool, have an impact on sales, etc..
3, lack of knowledge. In principle, of course, it could be possible that Mark and colleagues are simply not aware of the features we have implemented in openLCA to make PSILCA more transparent than the SHDB. This goes back to my old presentation of how LCA software influences what we can model and see [Ciroth, A. (2006): A new open source, LCA software , presentation, 7th Ecobalance conference, Tsukuba, presentation and conference transcript, pp. 427, November 14th – 16th, 2006].
role of software in sustainability assessment, [5]
If you only look into SimaPro, where new features are not shown, you are maybe not aware of them. However, I had direct talks with Mark about this topic and remember he said he regrets that it is difficult to implement.
The Deliverable has a specific annex where the “evaluation” is done in detail. It is a separate excel sheet, [6]. In this sheet, somehow data quality and uncertainty are part of transparency, reproducibility and documentation are addressed, but nothing specific for the social assessment apart from “are the relevant documentation, modeling data and model available […]”, see below.
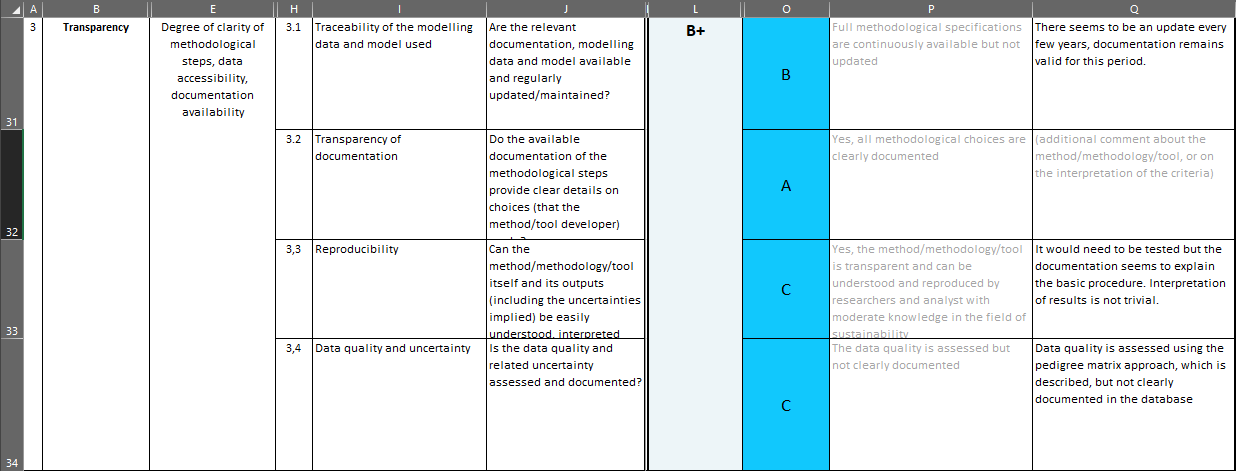
Evaluation of transparency in Orienting in a detailed excel sheet, SHDB
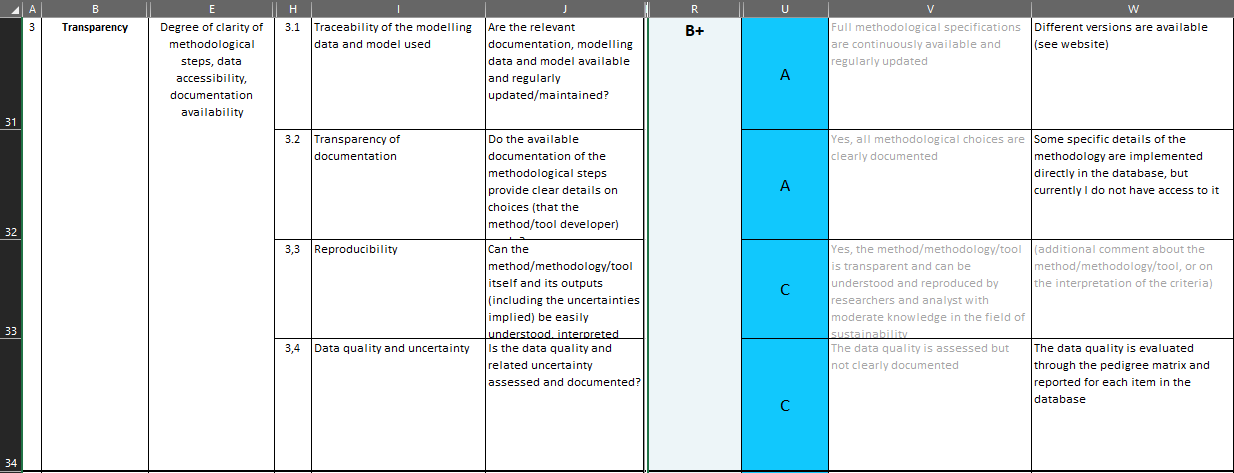
Evaluation of transparency in Orienting in a detailed excel sheet, PSILCA
Really striking is Cell W32, for PSILCA:
“Some specific details of the methodology are implemented directly in the database, but currently I do not have access to it”
The “evaluation” and overall assessment was seemingly done without having access to the PSILCA database. That’s how good scientific work should look like.
So, what are take-home messages?
1, I think the assessment of the two social LCA databases in the Orienting project is unfair and does not do justice to the PSILCA database which is more transparent than the SHDB.
2, this could be caused by commercial interest or by lack of knowledge; in both cases, a person who is affected by either commercial interest or lack of knowledge is not qualified to write such a deliverable. And it is even more a pity and disappointment if this deliverable is part of a unique project to advance sustainability assessment. Sorry Mark.
(three more things:
- apart from the transparency topic, there would be a lot more to say about the text, e.g. in the conclusion : “However, positive aspects are generally not considered in s-LCA databases, since databases are risk based. Therefore, the applicability limits itself to the identification of negative hotspots“ (p. 87). Risks are simply probabilities times impacts, if the impacts are positive, they become chances or opportunities. In PSILCA we have some indicators that address opportunities. And you can calculate social LCA in openLCA even directly so that no worker hours or similar are needed. This self limitation is another disappointment.
- quite some typos (“Eeora”) and maybe technical sloppiness that is not the idea to correct here in detail (but of course, how data quality and the pedigree matrices for example are discussed..).
- LCA is a small bubble where key players often wear several hats, and are somehow connected to different aspects of a “thing” they e.g. need to recommend about and design, as here, the social assessment. I am against a total not allowance of any involvement or connection of persons and even more so organisations to the matter of topic, as this may only lead to play games
(“no this is not done by somebody from a big LCA software company, this is done by an independent consultant who only with his other email is main coordinator of the database content for this company”).
But a declaration of the involvement, and a self-assessment of this involvement, that sounds needed. And is not provided here.
)